





Sql语句
SQL概述
SQL语句介绍
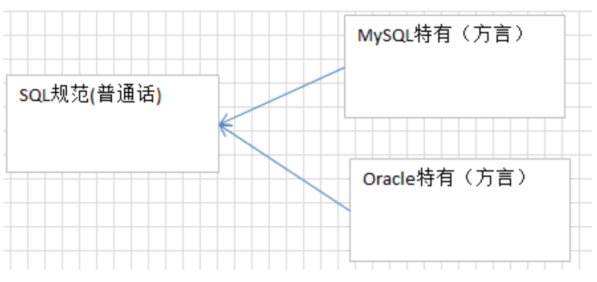
结构化查询语言(Structured Query Language)简称SQL,是关系型数据库管理系统都需要遵循的规范。 不同的数据库生产厂商都支持SQL语句,但都有特有内容。
扩展:SQL作为一种访问【关系型数据库的标准语言】,SQL 自问世以来得到了广泛的应用,不仅 是著名的大型商用数据库产品 Oracle、DB2、Sybase、SQL Server 支持它,很多开源的数据库产 品如 PostgreSQL、MySQL也支持它,甚至一些小型的产品如 Access 也支持 SQL。近些年蓬勃发 展的 NoSQL 系统最初是宣称不再需要 SQL 的,后来也不得不修正为 Not Only SQL,来拥抱 SQL。 蓝色巨人 IBM 对关系数据库以及 SQL 语言的形成和规范化产生了重大的影响,第一个版本的 SQL 标准 SQL86 就是基于 System R 的手册而来的。 Oracle 在 1979 年率先推出了支持 SQL 的商用产品。随着数据库技术和应用的发展,为不同 RDBMS提供一致的语言成了一种现实需要。 对 SQL 标准影响最大的机构自然是那些著名的数据库产商,而具体的制订者则是一些非营利机 构,例如【国际标准化组织 ISO、美国国家标准委员会 ANSI】等。 各国通常会按照 ISO 标准和 ANSI 标准(这两个机构的很多标准是差不多等同的)制定自己的国 家标准。
SQL作用
- 在数据库中检索信息。
- 对数据库的信息进行更新。
- 改变数据库的结构。
- 更改系统的安全设置。
- 增加或回收用户对数据库、表的许可权限。
SQL语句分类
- 数据定义语言:简称DDL(Data Definition Language)
- 作用:用来定义数据库对象:数据库,表,列等。
- 关键字:create,alter,drop等
- 数据操作语言:简称DML(Data Manipulation Language),
- 作用:用来对数据库中表的记录进行更新。
- 关键字:insert,delete,update等
- 数据查询语言:简称DQL(Data Query Language),
- 作用:用来查询数据库中表的记录。
- 关键字:select,from,where等
- 数据控制语言:简称DCL(Data Control Language),
- 作用:用来定义数据库的访问权限和安全级别,及创建用户。
SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾
- 可使用空格和缩进来增强语句的可读性
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
- 例如:SELECT * FROM user。
- 常用注释形式
1 | -- 单行注释内容 |
MySQL中的我们常使用的数据类型如下
| 类型名称 | 说明 |
|---|---|
| int(integer) | 整数类型 |
| double | 小数类型 |
| decimal (m,d) | 指定整数位与小数位长度的小数类型 decimal(10,2) |
| date | 日期类型,格式为yyyy-MM-dd,包含年月日,不包含时分秒 2019-05-06 |
| datetime | 日期类型,格式为 YYYY-MM-DD HH:MM:SS,包含年月日时分秒 2019-05-06 09:49:30 |
| timestamp | 日期类型,时间戳 |
| varchar(M) | 文本类型, M为0~65535之间的整数 |
DDL之数据库操作:database
创建、查看、删除、修改…
1) 创建数据库
1 | create database 数据库名; |
2)查看数据库
1 | 查看数据库服务器中的所有的数据库:show databases; |
3)删除数据库(慎用)
1 | drop database 数据库名称; |
4)修改数据库
1 | 修改数据库默认的字符集: |
5)其他数据库操作命令
1 | 切换数据库: use 数据库名; |
DDL之表操作:table
- 创建数据库表
- 查看表
- 快速创建:克隆
- 删除表
- 修改表结构:如果表内有数据,修改需要谨慎
- 字段更改字
- 段删除
- 修改表名称
1) 创建表
建立数据表,就是建立表结构,指定数据表中的一共有多少列,每一列的数据类型
1 | -- create 指的是【创建】,table 指的是【数据表】。 |
字段类型
常用的类型有:
- 数字型:int、integer、bigint、mediumint、smallint、tinyint
- 浮点型:double、float、decimal(精确小数类型)
- 字符型:char(定长字符串)、varchar(可变长字符串)
- 日期类型:date(只有年月日)、time(只有时分秒)、datetime(年月日,时分秒)、year
(年) - 二进制字符串类型:binary(定长,以二进制形式保存字符串)、varbinary(可边长)
单表约束
1 | 主键约束:primary key |
注意
1 | 主键约束 = 唯一约束 + 非空约束 |
2) 查看表
1 | 查看数据库中的所有表:show tables; |
3)快速创建一个表结构相同的表
1 | create table 新的表名 like 旧的表名; |
4)删除表
1 | drop table 表名; |
5)修改表
1 | -- 1.修改表添加列 |
DML数据操作语言
1)插入记录:insert
1 | -- 1.向表中插入某些列 |
5个注意事项:
- ① 列名数与 values 后面的值的个数相等
- ② 列的顺序与插入的值得顺序一致
- ③ 列名的类型与插入的值要一致.
- ④ 插入值得时候不能超过最大长度.
- ⑤ 值如果是字符串或者日期需要加引号’’ (一般是单引号)
2)更新记录:update
语法格式:update 更新、set 修改的列值、where 指定条件。
1 | - 1.不指定条件,会修改表中当前列所有数据 |
注意:
- ① 列名的类型与修改的值要一致
- ② 修改值得时候不能超过最大长度
- ③ 值如果是字符串或者日期需要加 ’ ’ 引号
3)删除记录:delete & truncate
语法格式:
1 | delete from 表名 [where 条件]; |
1 | truncate table 表名; |
注意
删除表中所有记录使用【delete from 表名】,还是用【truncate table 表名】?
删除方式的区别:
1 | delete :一条一条删除,不清空 auto_increment 记录数。 |
SQL约束
约束类型:
- 主键约束 primary key
- 唯一性约束 unique
- 非空约束 not null
- 外键约束 foreign key
主键约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
特点:
- 主键必须包含唯一的值。
- 主键列不能包含 NULL 值。
- 每个表都应该有一个主键,并且每个表只能有一个主键。
添加主键约束
- 方式一:创建表时,在字段描述处,声明指定字段为主键:
1 | CREATE TABLE persons( |
- 方式二:创建表时,在constraint约束区域,声明指定字段为主键:
- 格式: [constraint 名称] primary key (字段列表)
- 关键字constraint可以省略,如果需要为主键命名,constraint不能省略,主键名称一般没 用。
- 字段列表需要使用小括号括住,如果有多字段需要使用逗号分隔。声明两个以上字段为主键, 我们称为联合主键。
1 | CREATE TABLE persons_cons( |
- 方式三:创建表之后,通过修改表结构,声明指定字段为主键:
- 格式: ALTER TABLE persons ADD [CONSTRAINT 名称] PRIMARY KEY (字段列表)
1 | CREATE TABLE persons_after( |
删除主键约束
如需撤销 PRIMARY KEY 约束,请使用下面的 SQL:
1 | ALTER TABLE persons DROP PRIMARY KEY |
自动增长列
我们通常希望在每次插入新记录时,数据库自动生成字段的值。
我们可以在表中使用 auto_increment(自动增长列)关键字,自动增长列类型必须是整形,自动增长列 必须为键(一般是主键)。
- 下列 SQL 语句把 “persons” 表中的 “p_id” 列定义为 auto_increment 主键
1 | CREATE TABLE persons_id( |
- 向persons添加数据时,可以不为p_id字段设置值,也可以设置成null,数据库将自动维护主键 值:
1 | INSERT INTO persons_id (firstname,lastname) VALUES ('Bill','Gates'); |
- 默认AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下列 SQL 语法:
1 | ALTER TABLE persons AUTO_INCREMENT=100 |
非空约束
NOT NULL 约束强制列不接受 NULL 值。 NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记 录。
- 下面的 SQL 语句强制 “id_p” 列和 “lastname” 列不接受 NULL 值:
1 | CREATE TABLE persons_null( |
唯一约束
- UNIQUE 约束唯一标识数据库表中的每条记录。
- UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
- PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
注意:每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
添加唯一约束
与主键添加方式相同,共有3种
- 方式一:创建表时,在字段描述处,声明唯一:
1 | CREATE TABLE persons_unique( |
- 方式二:创建表时,在约束区域,声明唯一:
1 | CREATE TABLE persons( |
- 方式三:创建表后,修改表结构,声明字段唯一:
1 | ALTER TABLE persons ADD [CONSTRAINT 名称] UNIQUE (Id_P) |
删除唯一约束
- 如需撤销 UNIQUE 约束,请使用下面的 SQL:
1 | ALTER TABLE persons DROP INDEX 名称 |
- 如果添加唯一约束时,没有设置约束名称,默认是当前字段的字段名。
SQL语句之DQL【重要、重要、重要】
语法:查询不会对数据库中的数据进行修改,根据指定的方式来呈现数据。
语法格式:
1 | select * | 列名,列名 from 表名 [where 条件表达式] |
- select 是查询指令,可以读 1 ~ n 行数据;
- 列名换成 * 号,可以查询所有字段数据;
- 使用 where 来指定对应的条件
准备工作
创建商品表
1 | CREATE TABLE products ( |
简单查询
1 | -- 查询所有的商品 |
条件查询
使用条件查询,可以根据当下具体情况直查想要的那部分数据,对记录进行过滤。
SQL 语法关键字: WHERE
语法格式:
1 | select 字段名 from 表名 where 条件; |
运算符

1 | -- 查询商品名称为十三香的商品所有信息 |
逻辑运算符
| NOT | 逻辑非【**!】 |
|---|---|
| AND | 逻辑与【&&】 |
| OR | 逻辑或【||】 |
1 | select * from product where price > 40 and pid > 3; |
in 关键字
1 | -- in 匹配某些值中 |
指定范围中 between…and
1 | select * from product where pid between 2 and 10; |
模糊查询 like 关键字
模糊查询: 作用是帮助匹配模糊的字段内容
语法:where之后加上like 语法,%百分号,_下划线
% 代表任意长短内容模糊匹配:
- [%xxx]以xxx结尾的任意内容。
- [xxx%]以xxx开头的任意内容
- [%xxx%]包含xxx的任意内容
_代表任意一个字符的内容模糊匹配
- [_xxx]以任意单个字符开头的xxx内容。
- [xxx__x]
1 | -- 使用 like 实现模糊查询 |
排序
语法:
1 | select 字段名 from 表名 where 字段 = 值 order by 字段名 [asc | desc] |
1 | -- 查询所有的商品,按价格进行排序 |
聚合函数(组函数)
1 | 特点:只对单列进行操作 |
分组查询
分组查询:作用是将查询结果按照某列数据来进行分组呈现
语法格式:
1 | SQL 语法关键字:GROUP BY、HAVING |
1 | -- 根据 cno 字段分组,分组后统计商品的个数 |
注意事项:
① select 语句中的列(非聚合函数列),必须出现在 group by 子句中
② group by 子句中的列,不一定要出现在 select 语句中
③ 聚合函数只能出现 select 语句中或者 having 语句中,一定不能出现在 where 语句中。
having 和 where 的区别:
1 | 首先,执行的顺序是有先有后。 |
1) where
1 | 对查询结果进行分组前,将不符合 where 条件的记录过滤掉,然后再分组。 |
2)having
1 | 筛选满足条件的组,分组之后过滤数据。 |
分页查询
- 功能: 将查询的结果按照一页一页的形式输出
语法
1 | -- 语法 |
关键字:limit [offset,] rows 语法格式:
1 | select * | 字段列表 [as 别名] from 表名 |
limit 关键字不是 SQL92 标准提出的关键字,它是 MySQL 独有的语法。
通过 limit 关键字,MySQL 实现了物理分页。
分页分为逻辑分页和物理分页:
逻辑分页:将数据库中的数据查询到内存之后再进行分页。
物理分页:通过 LIMIT 关键字,直接在数据库中进行分页,最终返回的数据,只是分页后的数据。
1 | -- 如果省略第一个参数,默认从 0 开始 |
查询分类
- 条件查询 where
- 分组查询group by
- having针对分组结果过滤
- 排序order by
- 分页 limit
查询语句顺序:
- select 列 from 表 where 条件 group by 分组 having 过滤 order by 排序 limit 分页
